
With the plethora of available and ever-growing data produced every day, Machine Learning (ML) has become a buzzword from the past few years. Now-a-days, ML is used anywhere and everywhere from healthcare to education to e-commerce.
Learning Outcomes
- What is Machine Learning?
- A Quick History
- Need of Machine learning
- Types of Machine Learning Models
- Conclusion
ML is the field of study that learns from data, update itself, and then apply knowledge without being explicitly programmed. It mainly focuses on computer program that are able to learn and adapt to changes when exposed to new data. The machine learning model should be built to solve a particular problem independent of data set. The model should be such that given a problem statement, if it performs well on one dataset, it should work efficiently on other datasets too.
Let us understand the usage of ML with the help of an example, Suppose, we want to predict whether a patient has diabetes or not. Using classical algorithm, we will be needing some formula to compute the output. However, with ML model, no formula is needed but a model is trained on the dataset. The trained model is then use to generate prediction for all future patients about the disease with a great accuracy.
Learn from Data —–> Update Itself ——> Apply/ Behave Intelligently
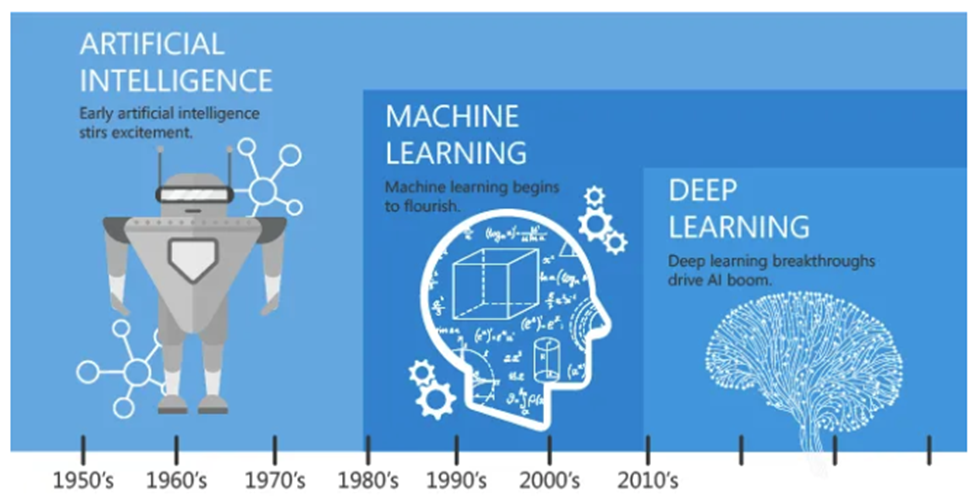
A Quick History
Source: https://towardsdatascience.com/
From the year of manually operated computer system, the idea has always been to build a computer that thinks and responds like human. In 1990s, Arthur Samuel defined ML after several years of stagnation of neural network to solve problem. The credit of machine learning to solve complex problem goes to the intersection of statistics and computer science.
Need of Machine Learning
A study shows that in the year 2021, 2.5 quintillion bytes of data is created every day while by the year 2025, 200+ zettabytes of data will be in cloud storage around the globe. With this ever-growing data, it becomes impossible for human to process the data, find patterns, and produce results. Here, the ML comes into picture!!
ML becomes necessity when:
- Data is massive
- Beyond human capability to explore the data to uncover patterns
- Problem is complex
- Data is unstructured
- Working with data is time consuming
- Improved Decision making is required
Types of Machine Learning Models
ML is majorly divided into three categories as shown in figure below.
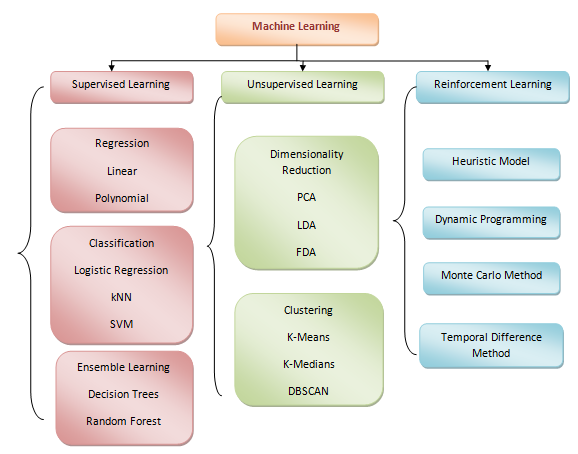
In this article, we will be discussing each of the three categories briefly with detailed explanation in upcoming articles.
1. Supervised Machine Learning
It is the first type of machine learning model which requires labeled data to train the algorithm. Every data point is tagged with some label. In other words, a supervisor is needed to teach the model which label will be given to data points.
To predict the label of each data point, the model has to be trained on some data with features and related labels. The goal is to train the model so well such that when we give new data as input, output is predicted with high accuracy.
In supervised learning, dataset is divided into two parts: train and test data. Firstly, the model is trained by passing features of train data, denoted by X and corresponding output (label) denoted by Y. The model learns the pattern in the dataset by predicting the output and then comparing it with actual output to find errors and improve. Once, the model is trained, test data is used to test the trained model to know the accuracy.
Supervised model is of two types: Regression and Classification
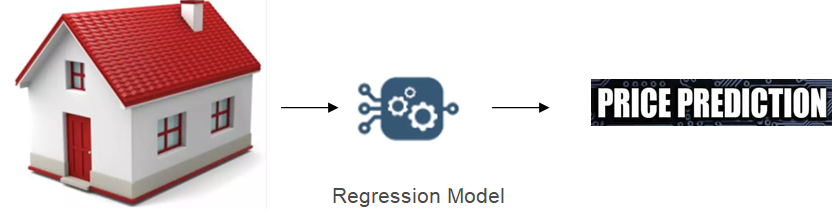
Regression models are used when we want the label as numeric value.
For instance, suppose we want to predict the price of the house. In this case, the input features will be number of rooms, terrace availability, locality and others. The output will be a continuous variable making it a regression problem.
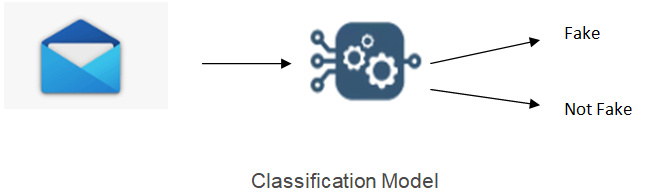
Classification models are used when the label is categorical.
For instance, suppose we want to identify whether the mail received is fake or not. At first, model will be trained with labeled data in which mail is marked as “fake” or “not fake”. After training, model is tested with some new data to get predicted label as output which are then compared with actual label to find the accuracy.
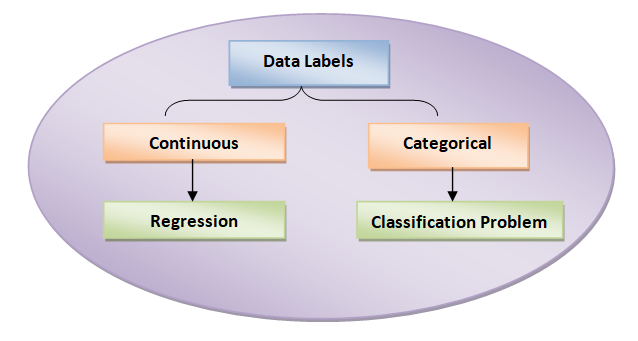
Data labels is always divided into two parts: continuous and categorical as shown in above figure. Based on the type of data label, problem is defined as regression or classification.
2. Unsupervised Machine Learning
In unsupervised learning, the models work with unlabeled data. As the name says, the model acts upon the data without any guidance. These models are used where no prior training is required and patterns within the data needs to be explored. It is just like a child learning without any guidance.
For instance, given brinjals, oranges, apples in a cluster and the task to segregate them into clusters. The data is given as input to the model and model segregates it into clusters based on similar features as shown in figure below.
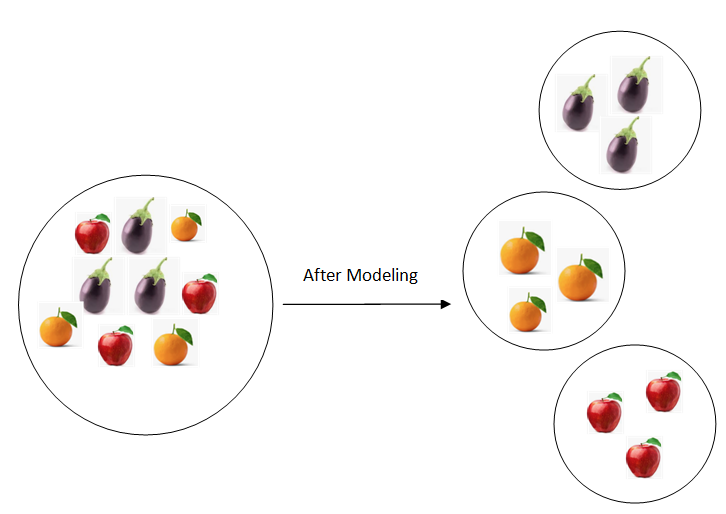
Unsupervised learning is majorly of two types: Clustering and Dimensionality Reduction
Clustering
In clustering, based on the similar features items or products are clustered into groups. Clustering algorithms in detail will be discussed in upcoming posts.
Dimensionality Reduction
It is used to express the data in fewer dimensions. For instance, suppose we have 108 features, it becomes difficult and time-consuming task to work with large number of features. For this, we make use of dimensionality reduction to reduce number of features without compromising the quality of data and hence accuracy of output.
3. Semi-supervised Machine Learning
It is the hybrid of supervised and unsupervised machine learning. It is useful in cases we have a small amount of labeled and huge amount of unlabeled data.
For instance, text document classifier is a problem where semi-supervised learning is useful. In this, half labeled and half unlabeled dataset is available, making this problem candidate for semi-supervised learning.
Conclusion
In this article, following points were focused:
- Basic definition and concept of machine learning has been explained.
- A quick history of machine learning is provided.
- Needs of Machine learning in real-world is discussed.
- Three major categories of ML namely supervised, unsupervised, and semi-supervised has been discussed with examples.
Let’s conclude by saying future is all about AI and Machine Learning.
Thanks for reading! Feel free to post your queries. I would be happy to help!!
Very informative source. Easy to understand the basics. Looking forward to learn more from this blog.