
With the upcoming and ongoing plethora of projects using Artificial Intelligence (AI) since the year 2021, the job roles in the field of data science has increased multi-folds. To build any data science project, understanding the life cycle and different phases involved in the process is important.
Learning Outcomes
- What is Data Science?
- Phases of Data Science Project
- Takeaways
Data Science
The most common buzz word in today’s time on Internet is “Data science”. Still if you asks about it’s definition, probably four different answers will come out of three different mouths.
Sticking to a definition for all articles, Data Science is a multidisciplinary branch of academia, research, and industry that combines programming competence, knowledge of statistics and mathematics, and domain knowledge to uncover and analyze information from data.
Some of the interesting examples of data science project include browsing a product on e-commerce platform and landing to a list of products under the headline “customers who bought this item also bought this”, a virtual world where a person can buy and sell products, news read by robots on news channels and much more.
One of the major reasons of Data Science becoming a demand is the large data bank available with organizations that can provide massive benefits.
“Oil fuels industrial economy, data science fuels digital economy”
Any data science project follows a life cycle which will be discussed in the next section.
Life Cycle of a Data Science Project
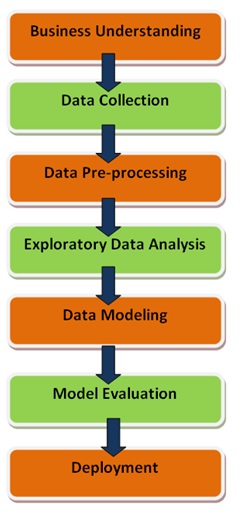
1. Business Understanding
The starting point of any project is the right understanding of business problem trying to solve. The fallacy in the identification of exact problem to be solved can lead to an undesired product leading to loss of customer’s trust. For instance, misunderstanding the business problem of developing a robot as a problem to developing a chatbot that talks with humans via chat.
To avoid any chaos in understanding of business problem, the approach of meeting with people whose business needs to be improved and asking appropriate questions needs to be adopted. The business needs should be transformed into appropriate data science questions and actionable steps.
“Your chances of creating fantastic data-driven products that have a positive organizational impact rise as you have a better grasp of the business problem”
2. Data Collection
After understanding the business problem, the next step is to collect the relevant data to work upon. The data collection is primarily essential. The major parameter in building an accurate model lies in quality data. The research says unreliable, incomplete, and unreliable data leads organization build a model of no use.
Data collected should reflect all features needed to solve the identified business problem. For instance, for the problem of recommending movies to the user, data should include age, demographic information, ratings and reviews given to other movies, social tags, and much more. But the data including height, shoe size, shirt brand, etc. would be inappropriate for recommending movies.
Data Extraction can be done using two ways:
- Web Scrapping
- Existing file format Data(CSV, XML, Text files, jSON)
3. Data Pre-Processing
The collected data in previous step needs to be cleaned and pre-processed to extract information of use before moving ahead in model building.
“Just like, pure gold though precious is of no use without processing, the data collected is of no use without processing“
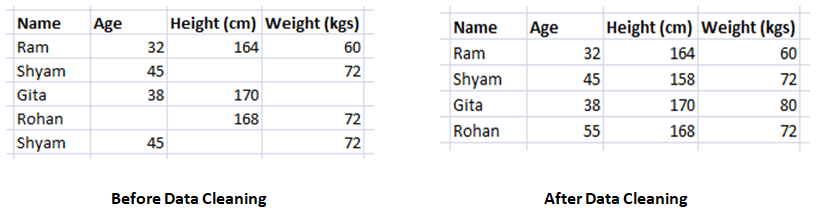
Ideally, data collected is unfiltered and unstructured. The model build without processing the data leads to results which will not make any sense, no matter how optimized your model’s hyper parameters are.
Quality data leads to accurate and efficient model. Several reasons due to which data pre-processing is important are:
- Inconsistent data type
- Missing Data
- Invalid Entries
- Duplicate or null values
“80% of the project time goes in Data Collection and Pre-processing part“
4. Exploratory Data Analysis (EDA)
As the name suggests, the motive is to explore data to learn about features, patterns, properties, figure out how to handle each feature, and much more.
Learn about Data!! Learn about Data!!
Several forms of EDA:
- Univariate and bivariate analysis
- Transformation
- Analysing data through plots
- Computing mean, median, and model to know data better.
- Outlier Analysis
- Finding any trends present
For example,
Suppose, we want to know the minimum value in each column, the same can be computed as shown below:
Import pandas as pd
data = [[10, 18, 11], [13, 15, 8], [9, 20, 3]]
df = pd.DataFrame(data)
print(df)
print(df.min())
Output:

5. Data Modeling (where magic lies)
The model is built at this stage. The first step is to split the data into training and testing. The model is built using the training data and then is tested for accuracy and efficiency on test data. Generally, data science problem is classified as supervised or unsupervised. Based on the problem to be solved supervised or unsupervised models can be used for training.
Listed below are supervised and unsupervised algorithms:
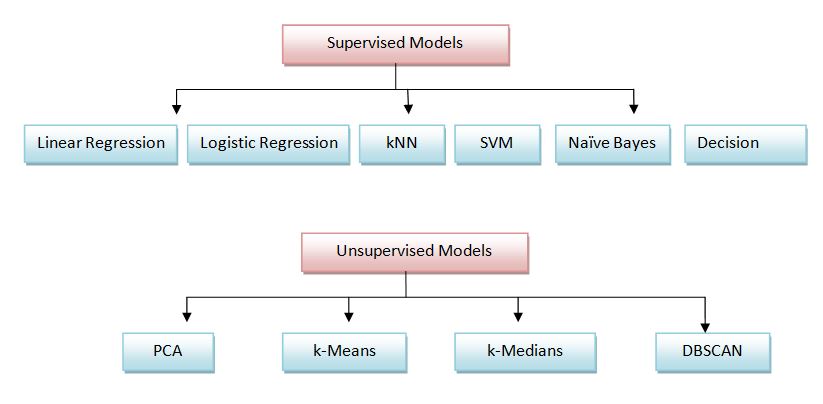
Based on the objective of the problem to be solved, appropriate model is picked and trained on the training data.
6. Model Evaluation
There are two major questions that are solved at this stage.
Q1. Given a particular problem, which model works best?
Q2. How well the selected model works?
To rightly evaluate the model, appropriate evaluation metrics should be considered. There may be cases where model gives 98% accuracy on training dataset but gives 30% accuracy on testing dataset. Further, model should not only rely on accuracy but several metrics.
For instance, suppose the problem is to recommend movies to the user, so precision should not only the sole criteria for evaluating the model but diversity to check the various domains from which recommendations are generated, popularity to ensure not only popular movies are recommended making popular movies more popular and less popular movies least popular. Based on the evaluation metrics, hyper parameters are tweaked to ensure good accuracy is not the result of particular dataset but a generalized one which works well on any unseen data.
Model should be robust, not underfitted or overfitted
Some of the most common evaluation metrics are: Precision, Recall, F-measure, Mean Absolute Error, Area Under Curve.
7. Deployment
The model trained has to be delivered in functional form to end-users. Model not deployed properly is of no use. Deploying the project is a cumbersome task and following the practice of “Deploy once and run forever” is bad.
Like every machine needs timely maintenance, model deployed also needs to be maintained from time to time. The model needs to be upgraded every interval just like any mobile application.
Following are some deployment frameworks:
- Django
- Flask
- FastAPI
Takeaways
In this article following points were focused:
- Basic definition and concepts of Data Science has been explained.
- Entire life cycle of any data science project is discussed.
- There are seven stages in any data science project.
- Every stage is explained in detail giving reader a complete idea of how data science project is built.
Thanks for reading! Feel free to post your queries. I would be happy to help!!